In any document, the frequency of occurrence of terms is taken as an important measure of score for that document (Term Frequency). For example : a document has total 100 words, and 30 words are 'mountains', we ,without hesitation, say that this document is talking about 'Mountains'.
But, if we only include most frequent word as our score metric, we will eventually loose the actual relevancy score of the document. Since same word could exist in number of documents and it's just frequent occurrence without adding much meaning to current context. In the above example : Suppose, there are two documents talking about 'Mt. Everest'. We obviously know that there will be higher occurrence of word 'Mountains'. But, if we use 'Term Frequecy (tf)' alone, term 'Mountains' will get highest weight rather than term 'Everest'. It's not fair. And, Inverse-Document-Frequency will tackle it.
Term Frequency (TF) / Normalized Term Frequency (nTF):¶
It simply measures the frequency/occurent of a term in a document. So, it gives equal important to all terms. Longer document could have large number of terms than smaller documents, so better to normalize this metric by dividing with total number of terms in the document. We also
Applications:¶
- Summarizing a document by extracting keywords.
- Comparing two documents (similary/ relevancy check)
- Search query to documents matching for building query results for search engine
- Weighting 'terms' in the document.
Inverse Document Frequency (IDF):¶
It gives the importance to more relevant/significant term in the document. It tries to lower the weights to terms having less importance. And, rare terms will get significant weights.
TF-IDF:¶
It tries to prioritize the terms based on their occurrence and uniqueness.
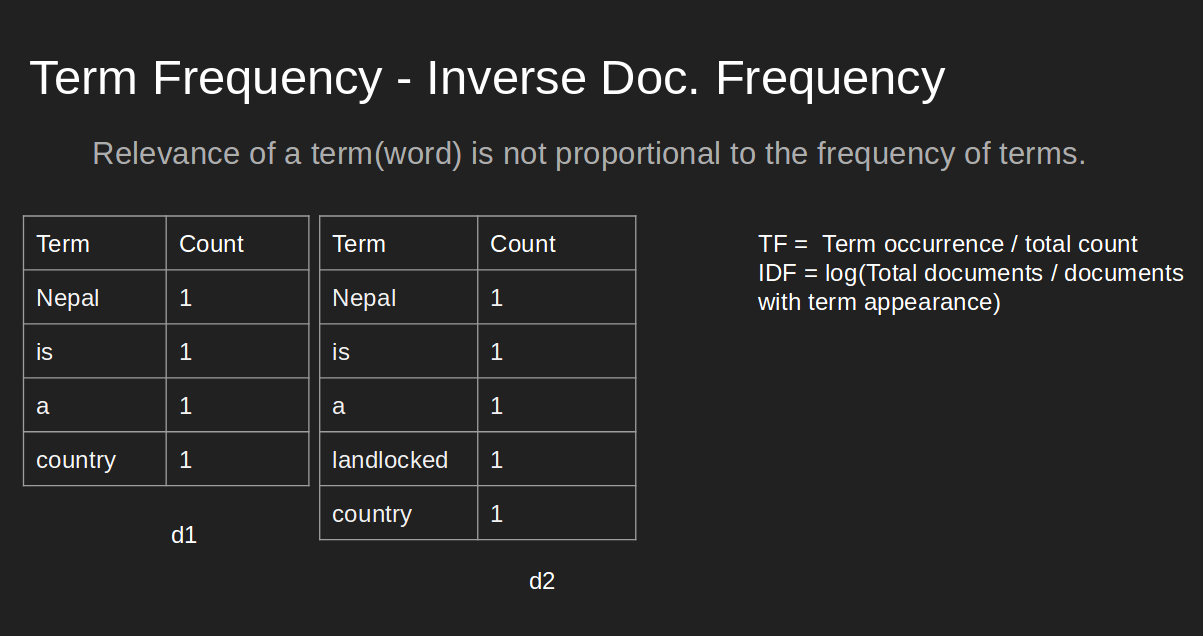


We can see that, although, term 'country' has prominent occurrence, 'tf-idf' gives priority to word 'landlocked' and it carries more information about the document.
NOTE 1 :¶
These weights are eventually used for vector-space model, where each term represents the axes, and document are the vectors on that space. Since 'tf-idf' value is zero (as shown above)' this representation is very sparse.
NOTE 2 :¶
Suppose, we are building a search engine system. The query is also converted into vector in vector-space model and compare with documents (NOTE 1) to get the similarity between them.